学生姓名:黎世骄
班班级级:车辆2018级-02班
指导教师:杜飞龙
毕设题目:基于多源时空数据的客运车辆监测预警系统


一、概况
1.选题意义
随着经济的快速发展和公路通车里程的不断增长,道路客运发展迅猛,客运车辆已成为我国旅客旅行的主要交通工具。但目前我国道路交通安全形势比较严峻,客运车辆特大交通事故屡有发生。资料显示,客运车辆事故是特大事故的主体,占特大事故近70%,尤以大型客车事故居多;客车特大交通事故由于其一次性伤亡人数较多,财产损失巨大,社会影响广,引起党中央,国务院,公安部的高度关注。同时,由于高经济效益,管理力量较薄弱的特点,非法营运客运车辆的数量也在增加,其不仅提高了交通道路出现事故的风险,还极大的扰乱了正常的社会和市场秩序。因此,合法营运客运车辆的有效管理与非法营运客运车辆信息的挖掘对促进与提高城市交通治理方面具有着重大的意义!
2.任务分解
1.了解业务相关数据,学习Just平台的使用方法。
2.学习轨迹数据挖掘方法,以及机器学习相关模型的理论与应用。
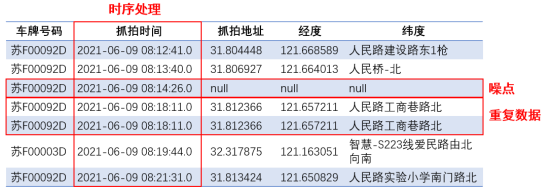
3.数据预处理,在建模之前完成数据调取,数据清洗与预处理工作,主要包括数据噪点消除,重复点消除,时序处理,驻留点检测等。
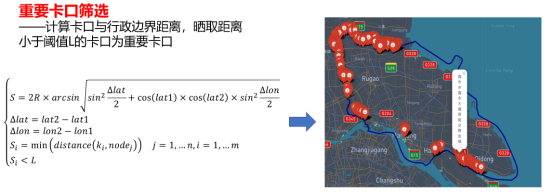
4.县际包车超范围模型建立与求解。通过下载开源路网数据,整理其元素关系完成行政边界可视化,通过计算不同卡口与行政边界的最短距离筛选重要卡口,最后将重要卡口在数据库中与车辆基本信息联接查询完成对包车超范围的车辆信息。
5.停运客运车辆复驶预警模型建立与求解。理清停运时间段的计算方法,通过对停运车辆进行停运时间段整理,及相关数据库操作完成对停运车辆复驶预警模型信息求解。
6.疑似非法营运客运车辆识别预警模型建立与求解。对营运车辆的营运特征进行调研与数据分析,总结车辆营运特点,并通过数据处理量化车辆的营运特征,在此基础上利用所学习的机器学习算法进行车辆的特征训练,完成对非法营运客运车辆的识别。
7.自学相关开发基础技能,完成java基础编程学习,学习并熟悉Vue,Flask开发框架.
8.系统开发。明确产品构架,流程,各模块功能, 使用Flask框架开发实现系统后端业务逻辑, 用Vue 开发前端组件,能够展示客运车辆相关数据。最后进行前后端联调交互,并测试bug,修改不完善点。
9.相关工作优化与毕业论文撰写。
3.已完成工作
1.数据调研分析工作:明确每个模型的输入与输出
2.理清每个模块的输入和输出需求,如下表所示。在这里先简单介绍一下这三个模型的功能定位。
预警模型 |
输入(字段) |
输出 |
车辆基本信息表 |
卡口数据表 |
县际包车超范围预警 |
车牌号码,经营范围, |
经度,纬度,抓拍时间,抓拍地址,车牌号码 |
预警车牌号码,卡口处抓拍地址,抓拍时间,经度,纬度 |
停运复驶预警 |
车牌号码,营运状态,车辆类型,修改时间 |
车牌号码,抓拍时间,抓拍地址,经度,纬度 |
停运复驶车牌号码,抓拍时间,抓拍地址,经度,纬度 |
疑似非法营运客运车辆识别 |
车牌号码,车辆类型,营运状态 |
车牌号码,抓拍时间,抓拍地址,经度,纬度 |
疑似非法营运车辆车牌号码,抓拍时间,抓拍地址,经度,纬度 |
3.数据预处理与数据清洗——噪点消除,重复点消除,时序处理,驻留点检测
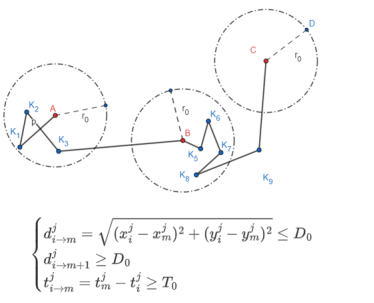
驻留点检测算法:
4.县际包车超范围预警模型建立与求解
5.停运客运车辆复驶预警模型建立与求解
通过对停运时间段的分析,我首先提出基于个体车辆监测方法,该方法主要流程是先将停运信息接入python环境中进行停运时间段分析,再将停运时间段返回至数据库中进行查询该时间段内车辆是否存在复驶行为。但这种方法存在一定缺陷,就是每查询一个车辆将伴随一次数据库的查询,那么车辆数目一旦增多,时间成本将大部分用在数据库操作上。经过预试验,发现每判断100辆车,就需要30分钟时间成本高。于是在此基础上我提出直接采用数据库操作的方法来完成。主要的思想是将正常营运状态车辆信息表与停运状态的车辆信息进行联接,并通过聚合函数等操作得到一张缓存的停运时间段的表,再将停运时间段的表与卡口信息表进行联接获取停运预警的结果。这个方法相比第一个方法减少了数据导出和导入多次查询的操作,大大减少了运行时间,全量数据的运行时间仅为3——5分钟。
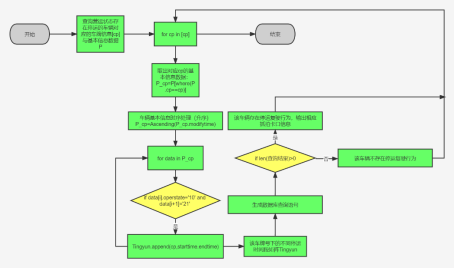
方法1
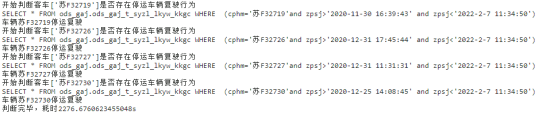
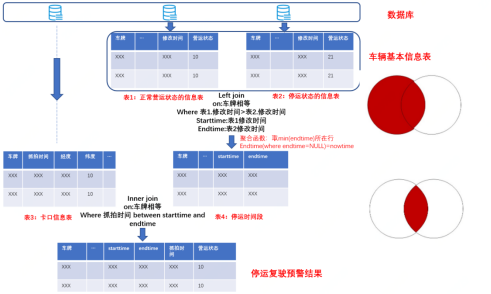
方法2
6.疑似非法营运客运车辆识别
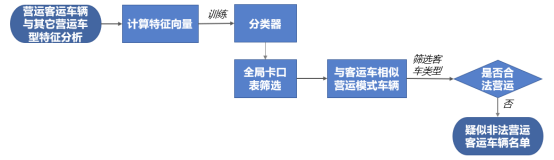
非法营运识别流程图
特征选取:
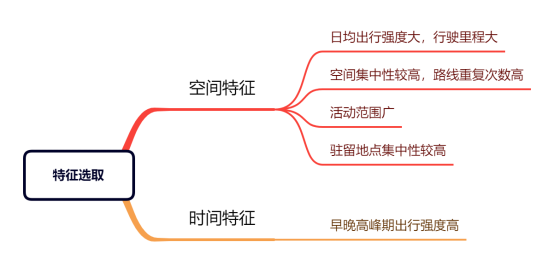
选取对象:合法营运客运车辆,营运牵引车辆,营运普通货车,营运轿车4种类型各1000辆作特征量化分析与比较。数据为交通部门所提供的卡口数据,选取时间:2021年6月7日——2021年6月12日。卡口数据量:702597条(非全量数据)
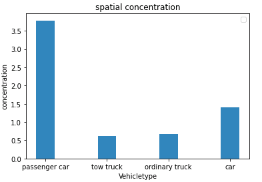
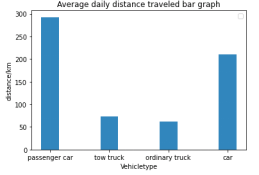
分析上述特征,通过距离分析,轨迹截断,驻留点提取,信息熵计算,卡口统计等方法完成对特征进行量化,得到4种车辆类型条形图分布如下。
活动范围特征:回旋半径 空间集中性:相似轨迹路段最大值
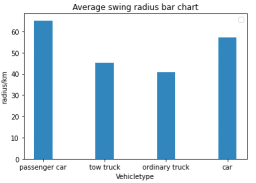
行驶强度:日均经过卡口次数 行驶强度:日均行驶里程
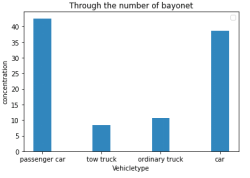
早晚高峰期强度 早晚高峰期强度占比
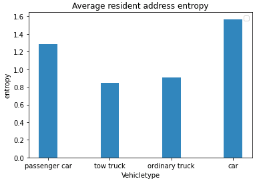
驻留集中性:驻留熵
特征向量t-SNE降维分布:用于体现特征表征方法的准确性,并对提出所假设进行佐证:
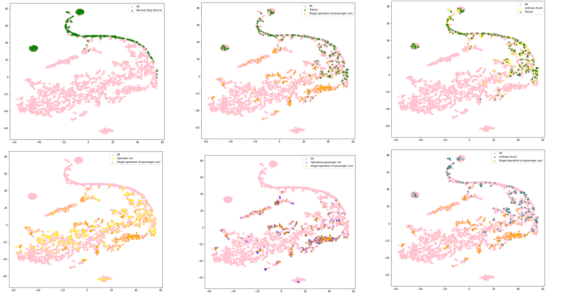
分类器调参学习与结果:
选取1000辆客运车辆与1000辆其他营运车辆,进行特征量化,再将特征向量打乱后,以7:3的比例分别抽出特征向量数据作训练集与测试集。通过现有的机器学习算法进行调参训练,最后通过该分类器对全局卡口进行筛选,选取客运车辆类型中不是合法营运的车辆标记为疑似非法营运客运车辆。

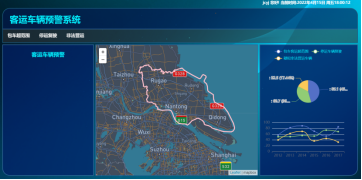
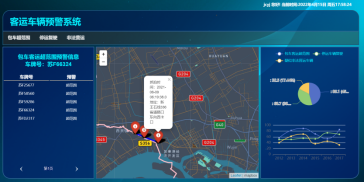
7.客运车辆监测预警系统
结合前三个模型的算法进行总结和封装,开发一个客运车辆预警系统,实现对客运车辆管理的可视化,辅助相关部门执法与工作。该系统由前端,后端,数据库三部分组成,其中前端用于将数据展示和渲染出可视化的页面,后端用于数据处理,接收前端需求和发送处理好的数据,数据库用于存储预警模型运行的结果及为后端提供数据查询工作,如下流程图展示所示。

页面展示:
三、下一步工作计划
完善毕业论文
优化前端页面

问题一:驻留点集中性,你提出利用信息熵来表示,其具体是怎么体现的,其中的p代表什么
回答:在驻留点集中这个特点引入信息熵是为了表征驻留点分布的不确定性,若熵值越大代表信息不确定性越大,熵值越小,说明信息不确定性越小。其中p代表驻留点次数占比。

在毕业设计完成的过程中,我认为自己在带着问题和求知去成长。刚开始,由于自身的编程基础,理论知识有限,在数据分析中常常会遇到很多问题,包括业务数据自身缺陷(数据稀疏,标签不足…),代码时长出现bug等。但通过每天的查阅文献,思考与总结,最终解决了项目模型上的一系列问题,同时提升了自己分析问题与解决问题的能力。为更深入了解系统的架构,通过自学前后端知识和交互,完成了前后端分离的搭建,加深了对业务逻辑与系统架构的理解。
在毕业设计过程中,由于一直在校外进行,在这感谢校内的导师,辅导员,同学对我的理解和帮助!
最后,伴随着毕业设计进入中后期阶段,我也即将本科毕业,希望通过最后的认真与努力给本科的学习生活划上圆满的句号!

